Speed-up numpy with Intel's Math Kernel Library (MKL)
The numpy package is at the core of scientific computing in python. It is the go-to tool for implementing any numerically intensive tasks. The popular pandas package is also built on top of the capabilities of numpy.
Vectorising computationally intensive code in numpy allows you to reach near-C speeds, all from the comfort of python. See, for example, this previous post in which I speed up a function provided by the PyMC3 project by over 500 times.
Numpy really is a great tool to use right out of the box. However, it’s also possible to squeeze even more performance out of numpy with Intel’s Math Kernel Library (MKL). In this post I will introduce Basic Linear Algebra Subprograms (BLAS) and see how choosing a different BLAS implementation can lead to free speed-ups for your numpy code.
Basic Linear Algebra Subprograms
Basic linear algebra subprograms are low level implementations of common and fundamental linear algebra operations. They are intended to provide portable and high-performance routines for common operations such as vector addition, scalar multiplication, dot products and matrix multiplications. Examples of BLAS libraries include OpenBLAS, ATLAS and Intel Math Kernel Library.
Numpy and BLAS
I’ve found that whatever machine I pip install numpy on, it always manages to
find an OpenBLAS implementation to link against. This is great, with no extra
steps compiling numpy from source and manually linking against a BLAS library,
we get the benefits of BLAS, all for free.
However, it’s also possible to link numpy against different BLAS implementations, which may or may not perform better on our particular CPUs. There are lots of different BLAS implementations out there, however here I’m going to focus on Intel’s Math Kernel Library, which is specifically designed for optimum performance on Intel chipsets.
Numpy and Intel’s Math Kernel Library
So, firstly, I should mention that Intel provide a python distribution explicitly intended to speed up computation on Intel CPUs. However, it is also possible to install select Intel-accelerated packages into a regular python distribution. In practice I prefer this latter method, finding it quicker to set up on a new system and giving me the illusion of more control.
To get an install of numpy compiled against Intel MKL it’s simple enough to pip
install intel-numpy. If you use scipy or
scikit-learn, it would be worthwhile to also
pip install intel-scipy intel-scikit-learn. If you already have a numpy
install, you should first pip uninstall numpy, to avoid any conflicts (and
similarly for scipy and scikit-learn, if you already have either of these
installed).
Speed comparison
Okay, great, so we can install select packages which are intended to perform better on Intel CPUs, but do they actually outperform OpenBLAS on your particularly system? Naturally, it’s time for a benchmark.
I’ve included all the code necessary to perform this benchmark on your machine here. To run these tests you’ll need virtualenv and bash (and python…). Give it a go and find out how Intel MKL performs on your machine. The comparison is made by computing a speed-up factor.
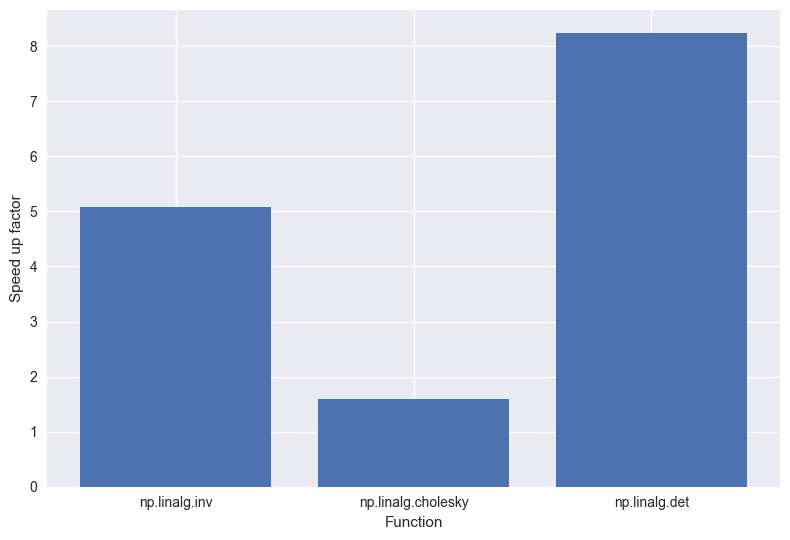
First, let’s take a look at how Intel MKL performs on some basic linear algebra operations. From the graph below we see that Intel MKL has outperformed OpenBLAS for the three functions we tested. In fact, computing the determinant of a matrix is over 8 times faster with Intel! Neat. And recall that we haven’t had to change any of our python code to get these speed-ups. These speed-ups are, for all intents and purposes, free.
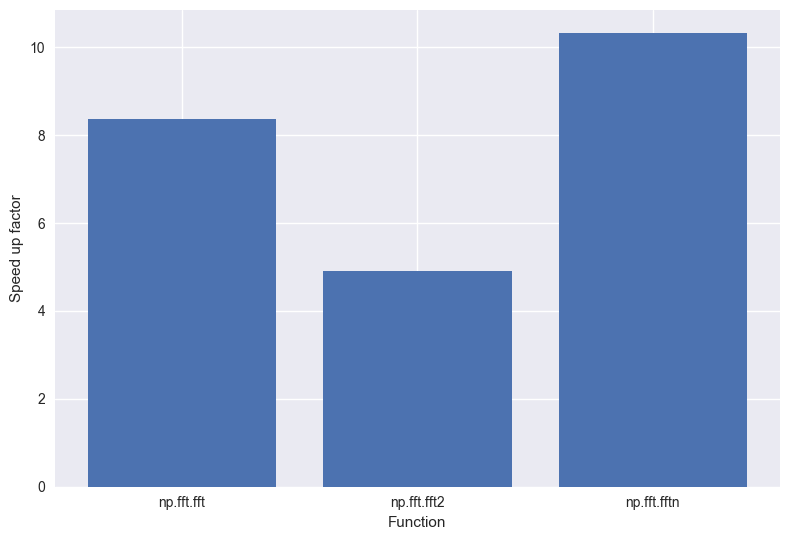
Next in line for inspection are numpy’s fast Fourier transform functions. I was
really impressed with the performance of Intel MKL on these functions:
np.fft.fftn was a huge 10x faster than the OpenBLAS linked numpy. If you’re
regularly using numpy to perform fast Fourier transforms you’d really feel the
benefit here.
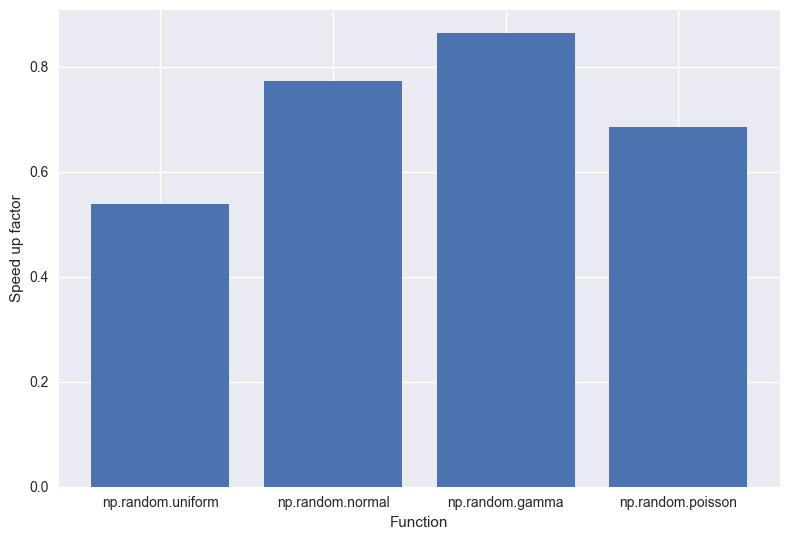
Finally, it was the go of random number generation. These were the results that surprised me the most. All the distributions I tested were actually slower with Intel. This I certainly did not expect. So, if you’re using numpy to do lots of random number generation, then you’d be better of staying with OpenBLAS.
Conclusion
BLAS libraries are a great way to squeeze extra performance from numerically intensive schemes. However, which BLAS library you choose can affect the performance of your code. In this post we compare the speed of numpy with OpenBLAS and numpy with Intel MKL. The code I used for benchmarking is provided here, and so the reader is encouraged to run these same tests on their machine, to assess performance on their exact setup. On my machine, at least, I found that Intel outperformed OpenBLAS on the fft tests and the linear algebra tests, but lagged behind on the random number generation.
Post-script
The results shown in the post were generated on my work desktop, which has the following stats:
Kernel Version: 5.3.0-22-generic
OS Type: 64-bit
Processors: 8 x Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
Memory: 15.5G of RAM